CryoGEN-I: MAP estimation under an energy prior
Reconstruct each degraded tomogram into its single most probable clean volume — with an energy prior and the $P_Y$ proxy, and no ground truth at all
CryoGEN-I is the starting point of the CryoGEN lineage: it takes a tomogram corrupted by noise and the missing wedge and reconstructs the single most probable clean volume it corresponds to — a MAP (maximum a posteriori) point estimate, with no ground-truth labels at all. It gives the lineage its simplest and most rigorous foundation; CryoGEN-II then lifts “per-image optimality” to global distribution matching, and CryoWGEN replaces the single answer with a whole family of reconstructions.
CryoGEN-I asks the most basic question: for each , what is the single most probable reconstruction ? That is a MAP problem. The catch is not the solving but the unseen prior : we have no labels for clean volumes, and no formula for the density of “what makes an look like real structure.”
The way out rests on one observation: if a guessed reconstruction is plausible, then rotating it by a random angle and re-applying the missing-wedge corruption should produce something that looks just like a real, observed tomogram. If the corrupted result looks unlike any real data, must be wrong. Real data is abundant — so “does it look like a real observation?” becomes the supervision signal. This is CryoGEN’s proxy idea.
The imaging model: turning unsupervised into matching in observation space
The whole CryoGEN lineage builds on the same degradation model:
Term by term: is the isotropic clean volume we want; is the missing-wedge operator, which carves out the wedge of Fourier space outside the tilt range — exactly what stretches a tomogram anisotropically along the missing direction; is Gaussian noise of variance ; and is the corrupted observation, the only thing we actually hold.
The key is to add a random rotation . The composite operator bridges the “clean reconstruction space ” and the “observed space ”: take any candidate , rotate it to a random orientation, apply the missing wedge, and you have projected it into observation space — where abundant real data is available to compare against. This bridge is what makes unsupervised learning possible: it translates “a reconstruction problem with no labels” into “does this match the real distribution in observation space?”
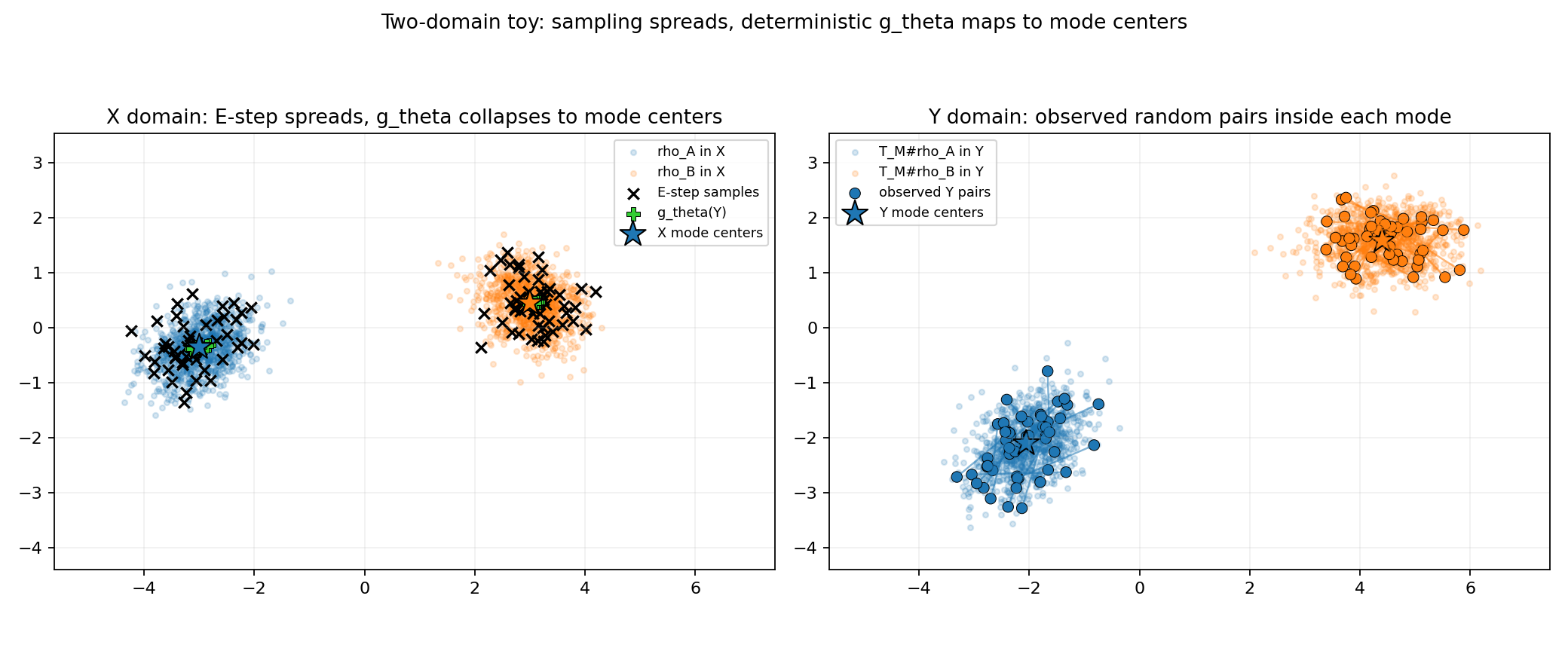
Two-domain toy example: left is the reconstruction space X, where E-step samples spread out and the network gθ collapses them to the mode centers; right is the observation space Y with paired real samples. Training alternates EM-style — the E-step samples candidate restorations, the M-step updates network parameters, and the discriminator (D-step) supplies the adversarial prior.
The energy prior: learning “plausible” as a scalar function
MAP needs the prior , which we cannot write down. CryoGEN-I parameterizes it as an energy function — a scalar network that scores a volume , where lower energy = more plausible. The bridge from energy to probability is the Boltzmann form:
Here is the energy with parameters ; the exponential turns “low energy” into “high probability”; and is the partition function, which integrates over all to normalize the density. The local minima of the energy are the modes of the density — to see how an energy function shapes its density, and how the depth of a well decides where probability mass concentrates, drag the one-dimensional example below:
Lower energy means higher probability: the two well bottoms become the two peaks of the density. Higher T flattens exp(−E/T), pushing the density toward uniform and erasing the contrast between the wells.
is a high-dimensional integral and intractable. But this is precisely where MAP helps: it only compares the energies of different and never needs — because is the same constant for every , it cancels in the .
So how is trained? Here the proxy does its second job: the energy can be trained entirely in observation space. Train a discriminator to tell real observations apart from corrupted reconstructions ; the boundary it learns is implicitly an energy separating plausible from implausible — an implausible does not look like real data once corrupted, so it is pushed to high energy. The prior never touches a single ground-truth label.
The MAP objective: balancing data fidelity against the energy prior
Putting the two pieces together, the MAP estimate is an optimization regularized by the prior:
The first term is data fidelity: once a candidate is corrupted () it must match the observation in hand, with the mismatch weighted by — the smaller the noise, the stricter this term. The second term is the energy prior: among all that explain the observation equally well, it pulls the solution toward the low-energy one, the one that most resembles real structure. The information the missing wedge erased is restored exactly through this second term — data fidelity has nothing to say about the missing frequencies inside the wedge, so the prior chooses for it.
Why is this the right weighting? For Gaussian noise , the likelihood is . Multiply it by the prior , take the negative log, and the constant terms (containing and ) are independent of and drop out — what remains is exactly the sum above. So CryoGEN-I is not an ad-hoc sum of two terms but the precise form of the log-posterior : the first term from the likelihood, the second from the energy prior.
What it achieves, and its limit
CryoGEN-I delivers a sharp single-point reconstruction: the missing wedge is filled in by the prior, noise is suppressed, and all of it without any ground truth. As the foundation of the lineage, it turns the seemingly impossible task of unsupervised reconstruction into a MAP problem with a clear objective and a clean derivation.
But it has two intertwined limits. The first is overconfidence: it returns a single point estimate per input — it neither learns a model that produces a distribution of reconstructions nor expresses the uncertainty the missing wedge ought to leave. The same corresponds to many that all fit, yet CryoGEN-I picks just one and tells you nothing about how uncertain it is. The second is training instability: the energy is learned by an adversarial min–max, and such objectives are prone to oscillation and mode collapse.
Falling back to variational inference to penalize directly does not work either — the EBM prior is only implicit, with no closed-form density or partition function, so the KL simply cannot be computed. This is what pushes CryoGEN-II to the optimal-transport route: it bypasses both the KL and the adversarial game, using a stable, single-potential objective to match the aggregate distribution — still one deterministic answer per observation, but more consistent and less artifact-prone.
Next see CryoGEN-II: distribution matching via optimal transport; the energy model behind the prior is in Energy-based models (EBM); the full lineage is on the methods overview.