CryoGEN-I:能量先验下的 MAP 估计
把每张退化断层图重构成最可能的那一个干净体 —— 用能量先验与 $P_Y$ proxy,全程无需真值
CryoGEN-I 是 CryoGEN 谱系的起点:它把一张被噪声和缺失楔形破坏的断层图 ,重构成它最可能对应的那一个干净体 —— 一个 MAP(最大后验)点估计,全程不需要真值标签。它给出整条谱系最简单、也最严谨的地基;后续 CryoGEN-II 把”逐张最优”升级为全局分布匹配,CryoWGEN 再把单点答案换成一整族重构。
CryoGEN-I 问的是最朴素的问题:对每一张 ,最可能的那一个重构 是什么? 这是一个 MAP 问题。难点不在”求解”,而在那个看不见的先验 :我们既没有干净体的标签,也写不出”什么样的 才像真实结构”的密度公式。
破局靠一个观察:若一个猜测的重构 合理,那么把它随机转一个角度、再用缺失楔形算子退化一次,得到的结果应当看起来就像一张真实拍到的断层图;若退化后的结果不像任何真实数据,则该 必然有误。真实数据十分充足 —— 因此可以拿”像不像真实观测”当作监督信号。这就是 CryoGEN 的 proxy 思想。
成像模型:把无监督变成观测空间里的匹配
整条 CryoGEN 谱系都建立在同一个退化模型上:
逐项看: 是我们想要的、各向同性的干净体; 是缺失楔形算子,在傅里叶空间挖掉倾转范围之外的那块楔形 —— 正是它造成了断层图沿缺失方向的各向异性拉伸; 是方差 的高斯噪声; 是我们手里唯一拥有的、被破坏的观测。
关键在再配上一个随机旋转 。复合算子 在”干净重构空间 “和”真实观测空间 “之间架起一座桥:任取一个候选 ,先随机转向、再施加缺失楔形,就把它投到了观测空间里 —— 那里有海量真实数据可以比对。无监督学习能成立,根基就在这座桥上:它把”没有标签的重构问题”翻译成”观测空间里能不能对得上真实分布”的匹配问题。
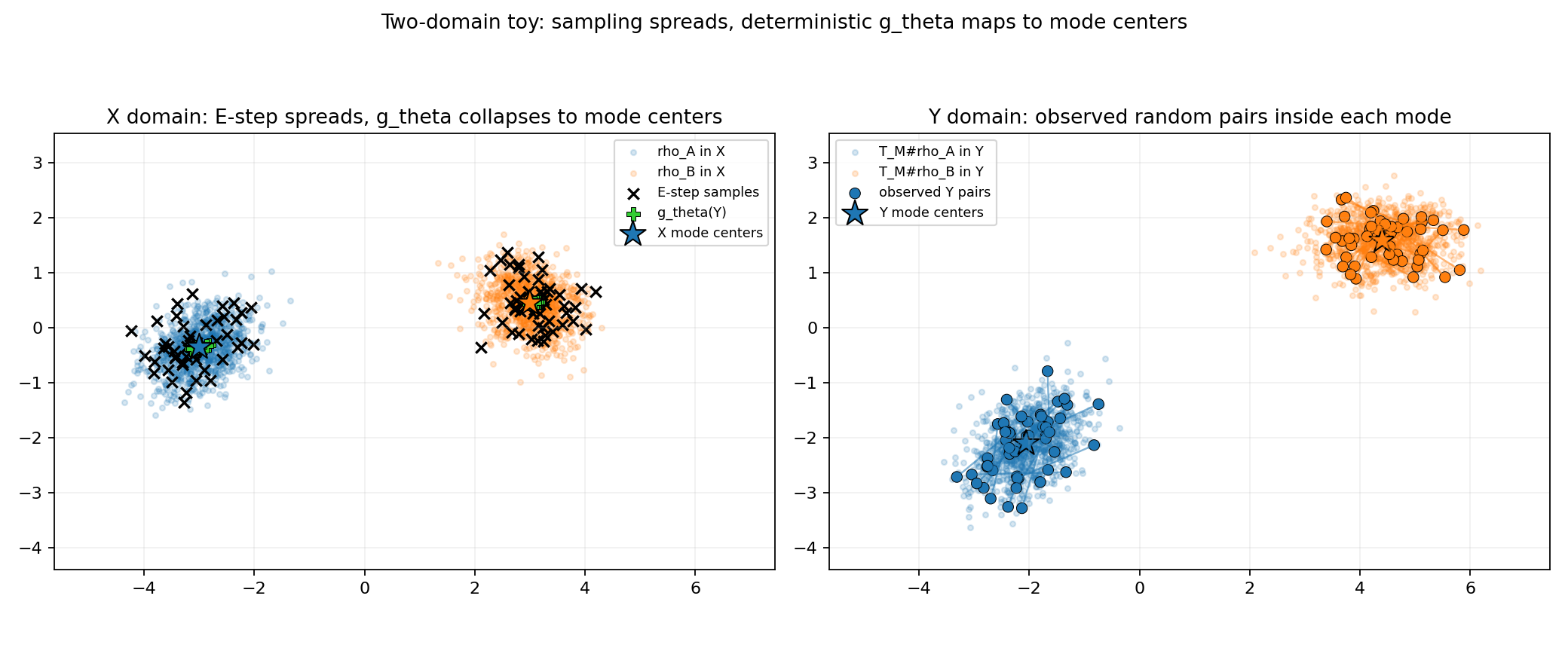
两域玩具示例:左为重构空间 X,E-step 采样铺开、网络 gθ 把它们收敛到各模式中心;右为观测空间 Y 里成对的真实样本。训练以 EM 方式交替进行 —— E-step 采样候选重构、M-step 更新网络参数,判别器(D-step)提供对抗先验。
能量先验:用一个标量函数把”合理”学出来
MAP 需要先验 ,而我们写不出它。CryoGEN-I 的做法是把它参数化成一个能量函数 —— 一个对体 打分的标量网络,能量越低 = 越合理。能量与概率的桥梁是玻尔兹曼形式:
是参数为 的能量;指数把”低能量”翻译成”高概率”; 是配分函数,它对所有 积分、把密度归一。能量的局部极小对应密度的众数 —— 想直观看一个能量函数如何塑造它的密度、势阱深浅又如何决定概率质量集中在哪里,可以拖动下面这个一维示例:
能量越低,概率越高:两个势阱底部对应密度的两个峰。温度 T 越高,exp(−E/T) 越平,密度趋向均匀,两峰之间的差异被抹平。
是高维积分、不可解。但 MAP 的好处恰在于:它只比较不同 的能量、从不需要算出 —— 因为 对所有 是同一个常数,求 时直接抵消。
那 怎么训?这里 proxy 第二次发挥作用:能量可以完全在观测空间训练。训练一个判别器去区分”真实观测 “和”退化后的重构 “;判别器学会的边界,隐式地就是一个区分合理/不合理 的能量 —— 不合理的 退化后不像真实数据,会被推向高能量。整个先验从未碰过一个真值标签。
MAP 目标:数据保真与能量先验的平衡
把两块拼起来,最终的 MAP 估计是一个带先验正则的优化:
第一项是数据保真:把候选 退化()后必须对得上手里的观测 ,偏差以 加权 —— 噪声越小、这一项越严苛。第二项是能量先验:在所有同样能解释观测的 里,把解拉向能量低、即更像真实结构的那一个。缺失楔形抹掉的信息正是靠第二项补回来的 —— 数据保真对楔形内那块缺失频率无话可说,先验替它做了选择。
为什么这一项配比是对的?对高斯噪声 ,似然 。把它与先验 相乘、取负对数,常数项(含 与 )与 无关、可丢弃,剩下的正是上式两项之和。所以 CryoGEN-I 不是凑出来的两项相加,而是对数后验 的精确形式 —— 第一项来自似然,第二项来自能量先验。
效果与局限
CryoGEN-I 给出的是一个锐利的单点重构:缺失楔形被先验补回、噪声被压低,且这一切不依赖任何真值。作为整条谱系的地基,它把”无监督重构”这件看似不可能的事,落实成了一个目标明确、推导干净的 MAP 问题。
但它有两个互相缠绕的局限。其一是过度自信:对每个输入只吐出一个点估计 ,既学不到能生成分布的模型、也无法刻画缺失楔形本应留下的不确定性 —— 同一张 其实对应许多个都说得通的 ,CryoGEN-I 却只挑一个、且不告诉你它有多不确定。其二是训练不稳:能量靠对抗式 min–max 学出,这类目标易震荡、易模式坍缩。
想退一步用变分推断、直接惩罚 ,又走不通 —— 因为 EBM 先验 只是隐式定义,没有可解的密度与配分函数,KL 根本算不出来。这正是 CryoGEN-II 改走最优传输的缘由:它绕开 KL 与对抗博弈,用一个稳定的、单势函数的目标做全局分布匹配 —— 仍是每个观测一个确定性答案,但更一致、更少伪影。
下一步见 CryoGEN-II:最优传输下的分布匹配;先验背后的能量模型见能量模型 (EBM);整条演化谱系见方法总览。